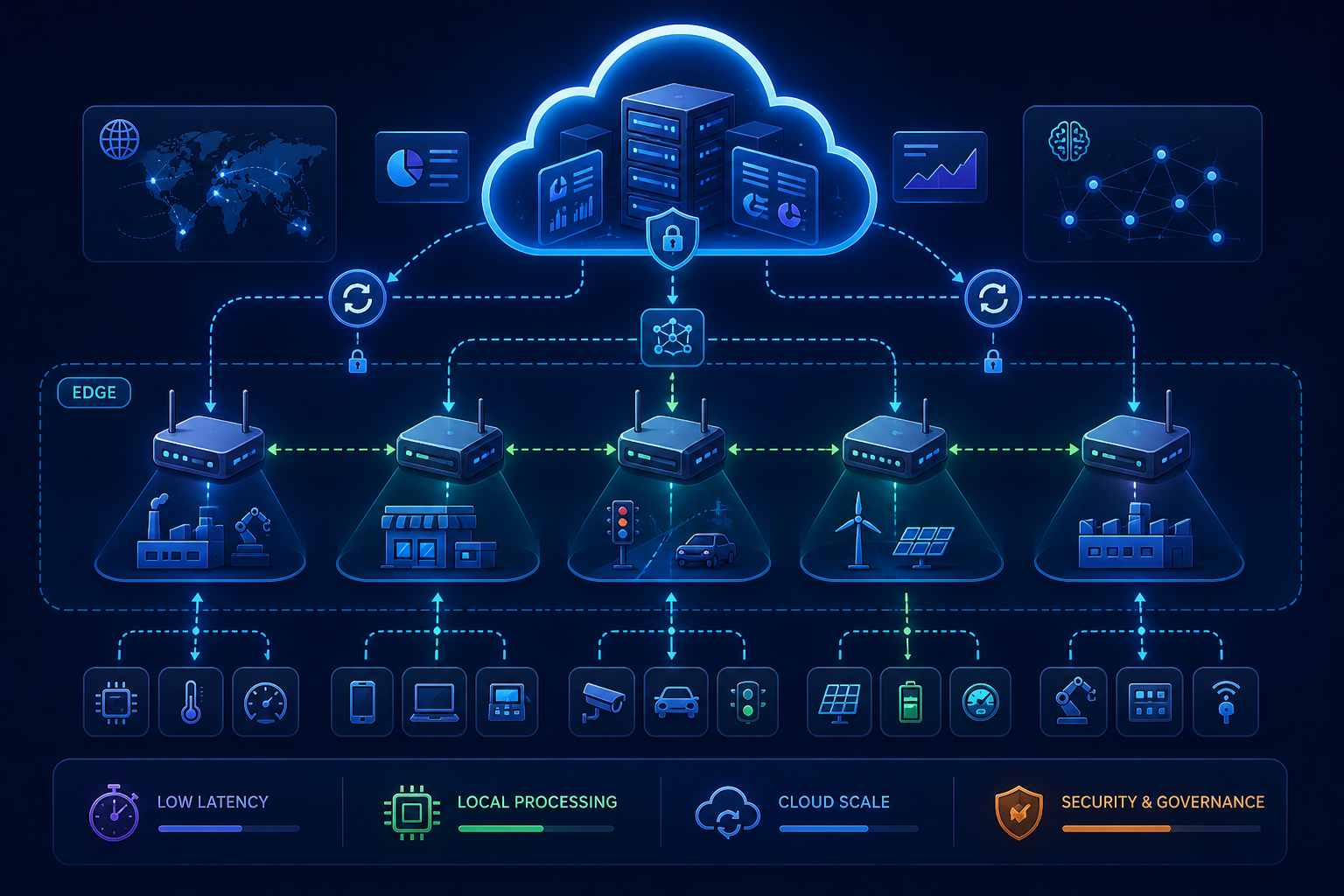
The architectural conversation around edge computing has oscillated between two extremes. One position holds that the edge is the future and that centralized cloud infrastructure will gradually recede as more computation moves closer to users. The opposite position holds that edge computing is a niche concern relevant only to a narrow set of latency-critical applications and that the operational complexity it introduces outweighs any performance benefit for most workloads. Neither extreme accurately describes how hybrid edge-cloud architectures actually function in production. The systems that handle significant scale today do not choose between edge and cloud. They deploy both, placing each workload where its specific requirements are best satisfied and managing the interaction between the two environments as a first-class architectural concern.
The question that matters is not whether edge or cloud will dominate. It is how to determine which workloads belong where and how to design the boundaries between them so that the overall system remains coherent, observable, and maintainable. This is a placement problem with architectural dimensions that extend beyond simple latency calculations. Workload placement determines data consistency guarantees and operational complexity and cost structures and failure modes. A decision that optimizes for response time may compromise correctness. A decision that simplifies deployment may multiply synchronization overhead. Understanding these tradeoffs systematically is what separates hybrid architectures that function reliably from those that accumulate fragility as they scale.
The Placement Decision: What Actually Determines Where Workloads Run
Latency is the most visible factor in edge placement decisions, but it is rarely the only factor that matters. A workload that requires sub-millisecond response times for user-facing interactions clearly benefits from edge deployment. But many workloads that are latency-sensitive in theory operate within acceptable bounds from regional cloud data centers in practice. The network is fast enough, the user population is concentrated enough, or the tolerance for delay is high enough that edge deployment adds complexity without delivering proportional user experience improvement. The placement decision must consider not just theoretical latency requirements but measured latency between actual users and available infrastructure, accounting for the last-mile variability that often dominates end-to-end response time more than the distance between edge node and origin server.
Beyond latency, data residency and sovereignty requirements increasingly determine workload placement. Regulations that restrict where certain categories of data can be processed and stored create hard constraints that override performance considerations. A workload that would be cheaper to run in a centralized cloud region may need to execute at edge locations within specific jurisdictions. These constraints are not technical preferences. They are legal requirements with compliance implications, and they are becoming more common rather than less. The architecture must accommodate them as first-class placement criteria rather than treating them as exceptions to be handled individually.
Workload characteristics also influence placement in ways that are less discussed than latency or compliance. Compute-intensive workloads that process large datasets benefit from cloud deployment where elastic resources can scale to meet demand. Stateful workloads that require frequent writes to consistent storage are easier to manage in centralized environments where strong consistency guarantees are achievable. Stateless, read-heavy workloads that serve cached or precomputed content are natural candidates for edge deployment. The placement decision for any given workload should reflect its actual computational profile, not a blanket assumption that edge is faster and cloud is cheaper. Speed and cost vary with workload characteristics in ways that simple rules of thumb obscure.
Latency-Critical Patterns That Actually Work
Edge deployment reduces latency by moving computation closer to users, but the magnitude of improvement depends on what the computation actually does. Serving static assets from edge caches produces dramatic latency reductions because the entire response can be assembled and returned from the edge node without contacting an origin server. Dynamic content that requires database access or backend computation benefits less because the edge node must still communicate with centralized services for data that cannot be cached or precomputed. The latency improvement for dynamic workloads comes from connection termination and TLS handshake proximity, not from moving the actual computation to the edge. Understanding this distinction prevents the common mistake of deploying workloads to the edge only to discover that the expected latency improvements never materialized because the edge node spends most of its time waiting for cloud services.
Effective low-latency edge architectures push computation to the edge in layers. The first layer handles connection termination, authentication, and rate limiting at the edge, reducing the round trips required before any application logic executes. The second layer serves cached or precomputed responses for content that changes infrequently or can tolerate staleness within defined bounds. The third layer executes lightweight application logic at the edge for operations that require user proximity but not centralized data access. A/B testing decisions, feature flag evaluation, personalization based on session-level context, all of these can execute at the edge without cloud communication. The fourth layer routes requests that require centralized computation to cloud services, but does so over persistent connections that avoid the overhead of establishing new connections for each request. This layered approach recognizes that latency optimization is not about moving everything to the edge. It is about moving the right things to the edge and optimizing the path for everything else.
The architectural implication of this layering is that edge and cloud are not separate environments but integrated tiers of a single system. The edge tier must have access to the configuration and context it needs to make autonomous decisions. The cloud tier must be reachable with minimal overhead when edge-tier processing is insufficient. The boundary between them must be designed as an architectural interface, not an operational afterthought, with defined contracts, timeout budgets, and failure modes.
Synchronization: The Hardest Problem in Hybrid Architecture
Distributing computation across edge nodes introduces synchronization requirements that centralized architectures avoid entirely. When multiple edge nodes serve the same user population or the same logical application, they must maintain consistent views of shared state or explicitly tolerate inconsistency. Neither approach is cost-free. Strong consistency across geographically distributed nodes requires coordination protocols that increase latency and reduce availability. Eventual consistency avoids coordination overhead but introduces the possibility that different nodes serve different versions of data, creating user-visible inconsistencies that are difficult to debug and even more difficult to explain to users who expect coherent experiences.
The synchronization patterns that function in production typically accept bounded inconsistency rather than pursuing either extreme of strong consistency or unbounded staleness. A configuration change propagates to edge nodes within a defined time window, and the system guarantees that no node will serve a version older than that window. User-generated data writes are accepted at the edge but confirmed only after propagation to a quorum of nodes or to a centralized authority. Read operations may return stale data within defined limits, but write operations are linearized to prevent conflicts. These patterns require infrastructure that can measure and enforce consistency bounds, not just eventually converge. The edge nodes must know how stale their data is and must be able to refuse operations that would violate defined consistency guarantees.
Conflict resolution for edge-originated writes introduces additional complexity. When two edge nodes accept conflicting updates to the same data before either has propagated its change, the system must resolve the conflict according to defined rules. Last-write-wins resolution is simple but loses data in ways that may be unacceptable for applications where both updates carried meaningful information. Merge-based resolution preserves data but requires application-specific merge logic that increases development complexity. Operational transformation and CRDT-based approaches provide automatic conflict resolution for specific data types but constrain the operations that can be performed at the edge. The choice of conflict resolution strategy is not purely technical. It determines what kinds of applications can function correctly at the edge, and it constrains the user experience in ways that product teams must understand before committing to edge-first architectures.
State Distribution and Cache Invalidation
Edge nodes operate most efficiently when they can serve requests from local state without consulting centralized services. This requires distributing state to the edge and maintaining its freshness through invalidation or update propagation. The mechanisms for doing this at scale differ substantially from traditional caching patterns. A CDN-style cache with time-to-live expiration is adequate for static content that changes infrequently and where staleness within the TTL window is acceptable. Dynamic application state requires more precise control over when edge nodes must refresh their local state and when they can serve from cache.
Invalidation-based approaches push notifications to edge nodes when state changes, allowing them to evict stale entries and fetch fresh data on demand. This minimizes staleness but requires reliable delivery of invalidation messages to all edge nodes that may be serving the affected data. At global scale with hundreds or thousands of edge locations, reliable invalidation delivery becomes a non-trivial distributed systems problem. Version-based approaches attach version identifiers to state and allow edge nodes to compare their local version against the current version before serving. This enables precise freshness control without requiring push-based invalidation but adds latency to every request that must verify its version. Hybrid approaches use push-based invalidation for frequently changing data and version checking for infrequently changing data, matching the synchronization mechanism to the access pattern.
The architectural principle that emerges from these patterns is that state distribution and cache coherence are first-class design concerns in hybrid edge-cloud systems. They cannot be deferred or handled by generic caching layers. The edge tier must understand the freshness requirements of each piece of data it serves and must have the mechanisms to meet those requirements without imposing excessive coordination overhead. Designing these mechanisms requires understanding not just the technical characteristics of the data but the business tolerance for staleness in the experiences that depend on it.
Operational Complexity and the Observability Challenge
Hybrid edge-cloud architectures multiply the number of locations where computation occurs and the number of paths through which data flows. An application deployed across fifty edge locations and three cloud regions has orders of magnitude more potential failure modes than the same application deployed in a single region. Observability infrastructure designed for centralized deployments strains under this distribution. Metrics aggregated across edge locations obscure location-specific degradations. Logs collected from distributed nodes are difficult to correlate without precise timestamp synchronization. Traces that span edge and cloud environments must maintain context across boundaries that lack shared infrastructure.
The operational response to this complexity involves several architectural commitments. Edge nodes must be instrumented to report health and performance independently, not just as aggregated statistics. Deployment mechanisms must support gradual rollout across edge locations with automated rollback when location-specific metrics degrade. Configuration management must ensure that edge nodes operate with consistent configuration while allowing for location-specific overrides when necessary. These operational concerns are architectural concerns. A system that cannot be effectively observed and managed across its distributed footprint will accumulate failures that centralized monitoring cannot detect.
The cost of operating a hybrid edge-cloud architecture must also be factored into placement decisions. Each additional edge location adds infrastructure cost, operational complexity, and surface area for failure. The latency improvement from adding an edge location must justify these costs. For applications with globally distributed users, the justification is typically clear. For applications with users concentrated in a few geographic regions, a smaller number of edge locations in strategic positions may deliver most of the latency benefit at a fraction of the operational cost. The optimal edge footprint is not a technical constant. It depends on the actual distribution of users and the latency sensitivity of their interactions.
What Hybrid Architecture Enables That Neither Edge Nor Cloud Achieves Alone
Hybrid edge-cloud architecture is not a compromise between two opposing approaches. It is an architectural pattern in its own right that enables capabilities neither environment can provide independently. Edge deployment alone cannot support workloads that require strong consistency or access to large centralized datasets. Cloud deployment alone cannot achieve the response times that latency-sensitive interactions demand. The combination, when designed intentionally, supports workloads that place latency-critical components at the edge while maintaining consistency and coordination through the cloud tier. This is not simply running some services in one place and some in another. It is designing the interaction between the environments so that the system as a whole achieves properties that neither environment could achieve on its own.
The architectural investment required to realize these benefits is substantial. Edge and cloud tiers must be designed as integrated components of a single system, with shared identity, consistent configuration, coordinated deployment, and unified observability. The synchronization mechanisms that maintain coherence between them must be reliable, efficient, and bounded in their failure modes. The operational practices that manage them must accommodate the distributed nature of the system without imposing coordination overhead that undermines the latency benefits the architecture was designed to achieve. These are non-trivial requirements. They explain why hybrid edge-cloud architectures remain less common than the theoretical benefits would suggest. But for systems that genuinely require both low latency and strong consistency, the investment is not optional. It is the cost of achieving the architectural properties the system needs, and the organizations that make this investment thoughtfully build systems that function in ways neither edge nor cloud architecture alone can replicate.









Comments (0)
No comments yet
Be the first to share your thoughts!
Post Your Comment Here: