Backend architecture has operated under a stable set of assumptions for decades. A request arrives, the system processes it, a response returns. The request-response cycle defines the boundaries of computation. Work begins when invoked and ends when the response is sent. State is managed within carefully bounded contexts. Failure means returning an error code or timing out. These assumptions are so fundamental that they have shaped everything from API design to database schemas to deployment patterns. Autonomous agents break every one of them.
An agent does not execute a single request and terminate. It pursues objectives across extended time horizons, sometimes minutes, sometimes hours. It makes decisions at runtime that alter its execution path in ways the original developer did not explicitly program. It invokes tools and external services not as a predetermined sequence but as a dynamic response to conditions it encounters. It reasons about partial results and adjusts its approach. When it fails, it does not simply return an error. It retries, replans, or escalates. These are not incremental extensions of existing backend patterns. They are fundamentally different computational behaviors that require fundamentally different architectural support. The shift from deterministic request processing to agent-driven execution is not a feature addition to existing systems. It is a structural transformation of what backend infrastructure must provide.
The Architectural Demands That Agents Introduce
Traditional backend services are designed around transactional boundaries. A request arrives, the system performs work within a defined scope, and the transaction completes or fails. The infrastructure assumes that work is bounded in time and that resources can be allocated and released within predictable windows. Agents violate these assumptions at every level. An agent pursuing a complex objective may need to maintain execution state across minutes or hours, far longer than any reasonable HTTP timeout. It may need to suspend activity while waiting for external conditions to change, resume when new information becomes available, and maintain coherent context across the entire duration. The infrastructure that supports this must provide persistence not just for data but for execution state itself, the ability to pause, checkpoint, and resume agent workflows without losing the reasoning chain that got the agent to its current position.
Beyond persistence, agents introduce variability in resource consumption that traditional capacity planning does not anticipate. A request has predictable resource requirements. An agent may invoke dozens of tool calls to complete an objective, each with different latency profiles and computational costs. The cumulative resource demand is not known at invocation time. It emerges as the agent executes. This requires infrastructure that can accommodate elastic resource allocation within a single logical workflow, scaling up when the agent enters a tool-intensive phase and scaling down during reasoning pauses. The architectural pattern shifts from allocating resources per request to allocating resources per objective, and the two are not equivalent.
Agents also invert the traditional relationship between application logic and infrastructure. In a conventional service, the application code determines what happens and the infrastructure provides the environment in which it happens. Agents introduce a layer of runtime decision-making that sits between the code and the outcome. The developer writes the tools and defines the objectives, but the agent determines which tools to invoke, in what order, and how to interpret the results. This means the infrastructure must support execution paths that were not explicitly programmed, which creates new categories of risk around observability, security, and cost control that backend systems have not historically needed to address.
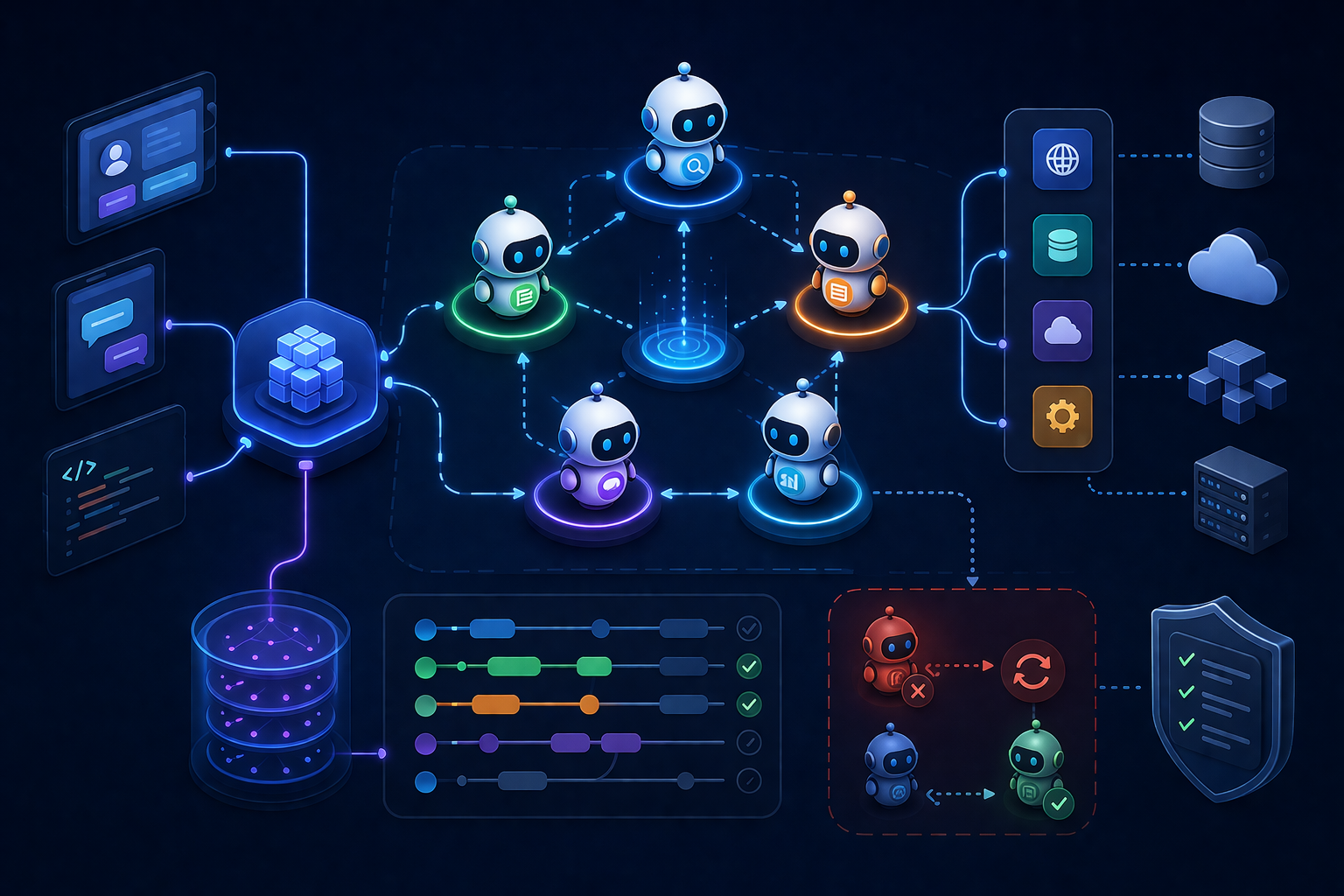
Multi-Agent Orchestration and the Problem of Coordination
Single agents introduce significant architectural novelty. Multiple agents cooperating on shared objectives introduce coordination problems that distributed systems research has studied for decades but that manifest differently when the coordinating entities are making autonomous decisions. When one agent delegates a subtask to another, the delegation carries context that must be preserved and made available to the receiving agent. When multiple agents contribute to a shared artifact, their contributions must be sequenced and merged in ways that respect the intent behind each contribution. When agents disagree about approach or intermediate results, the system must have mechanisms for resolving or escalating those disagreements without human intervention.
The orchestration patterns that emerge fall into several recognizable categories. Hierarchical orchestration assigns a supervisor agent that decomposes objectives and delegates subtasks to specialist agents, aggregating results as they return. This mirrors organizational structures in human teams and inherits similar failure modes. The supervisor becomes a coordination bottleneck and a single point of failure. Peer-to-peer orchestration allows agents to negotiate directly, discovering each other's capabilities and forming ad-hoc workflows. This reduces bottleneck risk but increases complexity in consensus formation and conflict resolution. Event-driven orchestration decouples agents entirely, with each agent publishing results to shared spaces that other agents consume. This maximizes flexibility but makes the overall workflow difficult to observe and debug.
Each pattern introduces distinct infrastructure requirements. Hierarchical orchestration needs reliable delegation mechanisms and timeout handling for subtasks that agents fail to complete. Peer-to-peer orchestration needs service discovery for agent capabilities and protocols for capability negotiation. Event-driven orchestration needs persistent event stores with guarantees about ordering and delivery. None of these requirements are met by conventional API infrastructure. They require architectural investment in coordination primitives that traditional backend systems do not provide.
Persistent Execution and the End of Stateless Services
The stateless service model that dominates contemporary backend architecture assumes that any instance can handle any request because all necessary state resides in external storage. This assumption breaks when agents maintain execution state that spans multiple tool invocations and reasoning steps. An agent in the middle of a complex objective cannot simply be load-balanced to a different instance if its current instance fails. The reasoning context, the history of tool calls and results, the intermediate conclusions the agent has drawn, all of this constitutes state that must survive instance failure and be available for resumption. This requires infrastructure that can checkpoint agent state at meaningful boundaries and restore it reliably when execution resumes.
The persistence model for agent workflows differs from database persistence in important ways. Database persistence is designed for structured data with defined schemas and query patterns. Agent state is semi-structured at best. It includes natural language reasoning traces, tool call histories with nested results, and partial progress toward objectives that may be defined in qualitative rather than quantitative terms. Storing this state efficiently requires different storage strategies than those optimized for transactional workloads. Retrieving it requires different access patterns than those supported by conventional query languages. The infrastructure must support append-only event logging that captures the full history of agent execution, point-in-time snapshots that enable efficient resumption, and indexing strategies that allow agents to retrieve relevant context from their own execution history without replaying the entire log.
This persistence requirement extends what it means for a service to be reliable. Reliability for a stateless service means that requests are handled within acceptable latency and error budgets. Reliability for an agent service means that objectives are eventually achieved despite interruptions, that execution state survives infrastructure failures, and that agents do not lose progress that required significant computation or external tool calls to produce. Meeting these requirements demands architectural investment in durability mechanisms that go well beyond what typical backend services provide.
Failure Handling When Failure Is Ambiguous
Traditional backend failure handling operates on clear signals. A connection timeout indicates network failure. A 500 response indicates server error. A null return indicates missing data. Each failure has a defined type and a defined response. Retry with backoff. Return a fallback value. Escalate to an operator. Agent failure is qualitatively different because agent actions can fail in ways that are ambiguous. A tool call that returns an unexpected result is not necessarily a failure. It may be a signal that the agent's approach needs adjustment. A reasoning step that produces a low-confidence conclusion is not an error. It is information the agent can incorporate into its next decision. The boundary between success and failure becomes a spectrum rather than a threshold, and the infrastructure must support nuanced responses across that spectrum.
Agents also introduce failure modes that traditional systems do not encounter. An agent may enter a loop where it cycles between approaches without making progress. It may pursue a reasoning chain that leads to a dead end. It may invoke tools in combinations that produce valid individual results but collectively achieve nothing. These are not failures in the traditional sense. No error is thrown. No timeout expires. The agent is functioning correctly according to its programming while failing to achieve its objective. Detecting these conditions requires infrastructure that can monitor not just whether agents are running but whether they are making progress toward objectives, measuring advancement through the objective space rather than just liveness of the process.
Recovery from agent-level failures requires capabilities that traditional retry logic does not provide. When an agent fails to achieve an objective, simply retrying the same approach with the same context is unlikely to succeed. Recovery may require the agent to replan, to decompose the objective differently, to seek additional information before proceeding, or to escalate to a human operator with a summary of what was attempted and why it failed. Each of these recovery paths requires infrastructure that can preserve the execution history that informs the recovery decision, provide mechanisms for the agent to modify its approach, and support escalation workflows that bridge autonomous and human-operated systems.
Observability When Execution Paths Are Emergent
Conventional observability assumes that the set of possible execution paths is known or at least bounded. Metrics are defined for expected operations. Logs capture specified events. Dashboards display anticipated patterns. Agent workflows violate these assumptions because the execution path is determined at runtime by the agent's reasoning, not at design time by the developer's code. The tools an agent invokes, the order of invocation, the interpretation of results, and the decisions that follow are all emergent properties of the interaction between the agent's model, the objective specification, and the environment the agent operates within.
Observing such a system requires different instrumentation strategies. Rather than instrumenting known code paths, the infrastructure must capture the full trace of agent execution, including reasoning steps, tool invocations, intermediate results, and decision points. This trace must be queryable not just by predefined metrics but by exploratory questions that operators formulate in response to unexpected behavior. Why did the agent choose this tool instead of that one? What evidence led to this conclusion? At what point did the agent's approach diverge from what a human operator would have expected? Answering these questions requires infrastructure that treats agent execution traces as first-class data, with storage and retrieval capabilities comparable to those provided for application logs and metrics.
The volume of observability data that agents generate also differs from traditional services. A single agent objective may produce dozens or hundreds of reasoning steps and tool calls, each generating its own trace data. Multi-agent workflows multiply this volume further. The infrastructure must accommodate this data volume without imposing prohibitive storage costs or query latency. This requires architectural decisions about what to capture, at what granularity, and for how long to retain it, tradeoffs that traditional observability systems were not designed to make at this scale.
Security Boundaries When Agents Act Autonomously
Traditional backend security operates on the principle that code executes with defined permissions and accesses resources through controlled interfaces. The code does what it was programmed to do, and security boundaries enforce what it is permitted to do. Agents complicate this model because they determine at runtime which tools to invoke and with what parameters. A tool that is safe when invoked with certain inputs may become dangerous when invoked with others. A sequence of tool invocations that is individually benign may collectively produce unintended effects. The security model must account not just for what the agent is permitted to do but for what it might decide to do based on its reasoning, and reasoning is inherently less predictable than programmed logic.
The architectural response to this challenge involves layered security boundaries that operate at the tool level rather than the service level. Each tool available to an agent must carry its own permission model, with constraints on what parameters it can accept and what side effects it can produce. The agent's execution environment must enforce these constraints regardless of what the agent decides. This means the infrastructure must provide tool execution sandboxes that validate invocation parameters against defined policies, rate limits that prevent runaway tool usage, and cost controls that bound the cumulative resource consumption of agent-driven workflows. These are security concerns that traditional API gateways and service meshes are not designed to address.
What This Means for Backend Architecture
The architectural implications of agent-driven computation extend beyond any single component. Supporting autonomous agents requires infrastructure that provides persistent execution state, coordination primitives for multi-agent workflows, observability for emergent execution paths, and security boundaries that operate at the tool level. These are not features that can be added to existing backend services through incremental improvement. They represent a distinct set of architectural requirements that will shape the next generation of backend infrastructure.
The systems that successfully support agent workflows will be those that treat execution as a first-class concern, with the same level of architectural investment that databases receive for data persistence and message queues receive for asynchronous communication. Execution state must be durable, queryable, and resumable. Coordination must be reliable, observable, and efficient. Failure handling must be nuanced, supporting partial progress and replanning rather than binary success or failure. These requirements are not speculative. They are emerging now in systems that push the boundaries of what autonomous agents can do. The architectural patterns that satisfy them will define backend design for the next decade, just as the shift to stateless services and API-driven architectures defined the previous one. The transition is already under way. The only question is whether backend infrastructure will evolve to meet the requirements or whether agents will be constrained by architectures that were designed for a different era of computation.









Comments (0)
No comments yet
Be the first to share your thoughts!
Post Your Comment Here: